一. vector的概念
向量(Vector)是一个封装了动态大小数组的顺序容器(Sequence Container)。跟任意其它类型容器一样,它能够存放各种类型的对象。可以简单的认为,向量是一个能够存放任意类型的动态数组。
Vector的特点:
- vector是表示可变大小数组的序列容器。
- vector就像数组一样,也采用的连续空间来存储元素,这也意味着可以采用下标对vector的元素进行访问。
- 普通数组相比,vector的大小可以在运行时自动调整,根据需要增加或减少容量。

- 当vector需要重新分配大小时,其做法是,分配一个新的数组,然后将全部元素移到这个数组当中,并释放原来的数组空间。
- vector分配空间策略:vector会分配一些额外的空间以适应可能的增长,因此存储空间比实际需要的存储空间一般更大。不同的库采用不同的策略权衡空间的使用和重新分配,以至于在末尾插入一个元素的时候是在常数的时间复杂度完成的。
- 与其它动态序列容器相比(deque, list and forward_list), vector在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list和forward_list统一的迭代器和引用更好
二. Vector的使用
需要包含头文件:#include<vector>
vector的构造
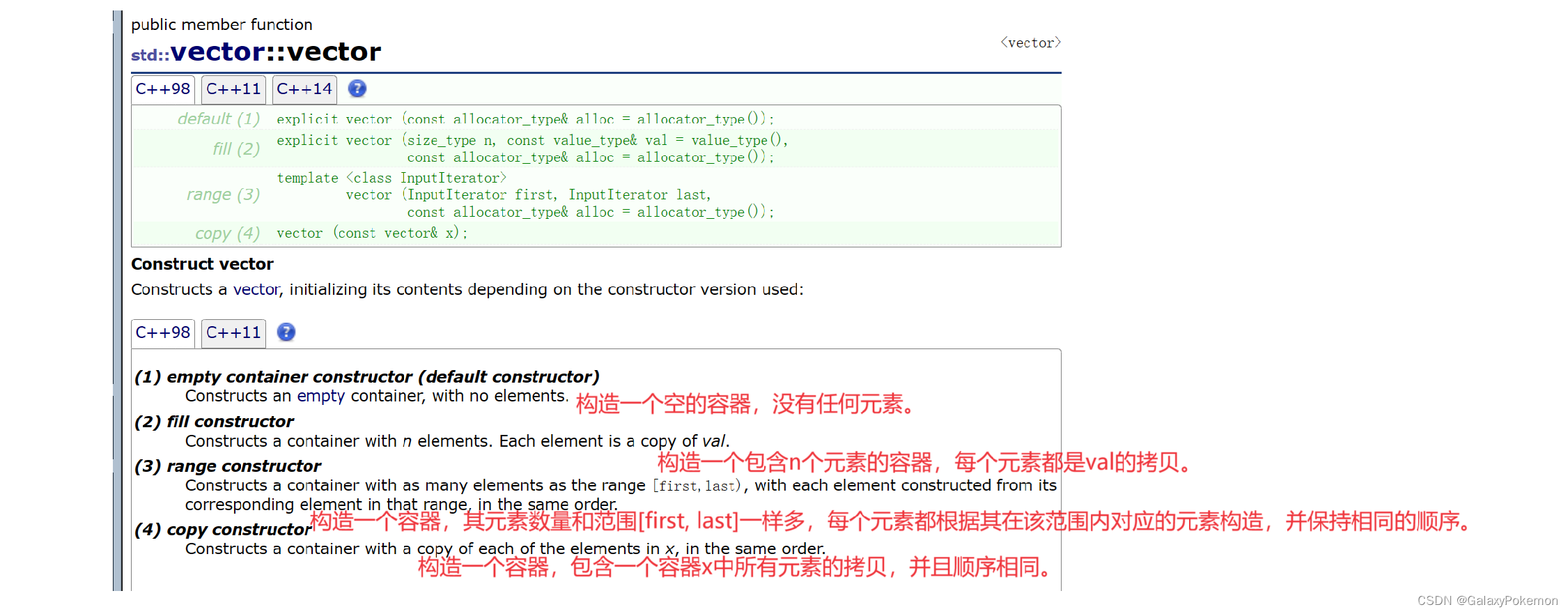
explicit vector (const allocator_type& alloc = allocator_type());
explicit vector (size_type n, const value_type& val = value_type(),
const allocator_type& alloc = allocator_type());
vector (InputIterator first, InputIterator last,
const allocator_type& alloc = allocator_type());
vector (const vector& x);
//alloc: 分配器对象。容器保留并使用一个这种分配器的内部拷贝。成员类型allocator_type是容器使用的内部分配器类型,定义在vector中作为其第二个模板参数(Alloc)的别名。如果allocator_type是默认分配器的一个实例化(默认分配器没有状态),这不相关。
//n: 初始容器大小(即,在构造时容器中的元素数量)。成员类型size_type是一个无符号整型类型。
//val: 用来填充容器的值。容器中的每一个n元素将会初始化为这个值的一个拷贝。成员类型value_type是容器中元素的类型,定义在vector中作为其第一个模板参数(T)的别名。
//first, last: 指向范围内初始和最终位置的输入迭代器。使用的范围是[first, last],其中包括所有first和last之间的元素,包括由first指向的元素但不包括由last指向的元素。函数模板参数InputIterator应该是一个输入迭代器类型,它指向可以构建value_type对象的元素类型。
//x: 另一个相同类型的vector对象(具有相同的类模板参数T和Alloc),其内容被复制或获取。int main()
{
vector<int> v1; //构造int类型的空容器
vector<int> v2(10, 2); //构造含有10个2的int类型容器
vector<int> v3(v2); //拷贝构造int类型的v2容器的复制品
vector<int> v4(v2.begin(), v2.end());//自己类型的迭代器进行初始化
for (auto e : v4)
{
cout << e << " ";
}
cout << endl;
string s1 = "GalaxyPokemon"; //其他容器的迭代器进行初始化
vector<char> v5(s1.begin(), s1.end());
for (auto e : v5)
{
cout << e << " ";
}
cout << endl;
//还能用数组进行初始化,本质是指针,数组名代表首元素的地址
int arr[] = { 1,2,3,4 };
vector<int> v6(arr,arr+4);
for (auto e : v6)
{
cout << e << " ";
}
return 0;
}
为什么不能用cout<< v1 <<endl直接访问呢?
C++标准库中的
vector没有重载<<运算符来支持直接打印。因此,直接尝试用cout打印vector会导致编译错误。

外传:vector<char> strV能不能替代string str,它们两个都是字符数组,也都能动态增长呀?可以替代吗?
答案是否定的:
他俩结构上有所不同
string和vector<char>的处理和终结字符\0的方式确实有所不同。string 和
\0C++ 中的
std::string类自动处理字符串的终止字符\0。为了更好的兼容C接口,当你使用std::string存储文本数据时,无论是通过构造函数、赋值操作还是添加内容,std::string都会在内部确保字符串后面有一个\0字符。这意味着你可以安全地将std::string的内容传递给期望以 null 结尾的 C 字符串的 C 函数(如strcpy,printf, 等等)。std::string s = "hello"; std::cout << s.c_str(); // c_str() 返回一个以 '\0' 结尾的 const char* 指针vector<char> 和
\0与
std::string不同,std::vector<char>不会自动在其元素后添加\0字符。vector<char>只是一个字符的动态数组,它不假设存储的数据是字符串。因此,如果你想用vector<char>来存储字符串并传递给期望以 null 结尾的字符串的 C 函数,你需要自己管理并在适当的位置添加\0。std::vector<char> v = {'h', 'e', 'l', 'l', 'o'}; v.push_back('\0'); // 必须手动添加 '\0' std::cout << &v[0]; // &v[0] 现在指向一个以 '\0' 结尾的字符数组如果你的目的是处理文本字符串,推荐使用
std::string,因为它自动处理与字符串相关的许多细节,包括\0的添加。使用std::vector<char>来处理字符序列或者非文本的二进制数据更加合适,因为这时你可能不需要字符串的特定行为,如自动添加终止字符。string的接口比vector更丰富
1. 功能和方法
- 专用方法:
string类提供了大量专门用于字符串处理的方法,如substr(),find(),replace(), 和append()等。这些方法使得处理文本和字符串操作更加直观和高效。- 字符操作:虽然
vector<char>也支持类似push_back()和pop_back()这样的操作,但缺乏专门针对字符串处理的优化和功能。2. 性能
- 内存管理:
string通常对字符串操作进行了优化,包括内存的分配和重新分配。虽然vector<char>也提供动态大小调整,但它的内存管理策略并不专门为字符串优化。- 效率:对于一些操作,如连接两个字符串,
string的+操作符或append()方法通常比vector<char>的元素逐一添加更高效。3. 语义清晰性
- 可读性:使用
string类型可以使代码的意图更加明显,即处理的是文本数据。而vector<char>更多地被看作是字符的集合,它在语义上不如string直观。虽然可以使用
vector<char>来代替string,但在处理字符串时,使用string类通常更加合适、高效和符合语义。vector<char>适合于需要灵活处理字符数据的情况,尤其是当涉及到字符级别的复杂操作时。因此,在大多数涉及文本处理的场景中,推荐使用string而非vector<char>。
vector里面能存string吗?
单参数的构造函数支持隐式类型的转换
explicit vector (const allocator_type& alloc = allocator_type());
explicit vector (size_type n, const value_type& val = value_type(),
const allocator_type& alloc = allocator_type());
vector (InputIterator first, InputIterator last,
const allocator_type& alloc = allocator_type());
vector (const vector& x);
// 创建一个空的vector。
std::vector<int> v;
//创建一个给定大小的vector,使用元素的默认构造函数初始化所有元素。
std::vector<int> v(10);
//创建一个给定大小的vector,并初始化所有元素为指定的值。
std::vector<int> v(10, 5); // 10个元素,每个都是5
//通过一对迭代器给定范围创建vector。
std::array<int, 5> arr = {1, 2, 3, 4, 5};
std::vector<int> v(arr.begin(), arr.end());
//通过另一个同类型vector创建一个新的vector的副本。
std::vector<int> original(10, 5);
std::vector<int> v(original);
不仅可以用自己类型的迭代器,还能用其他能匹配上的类型的迭代器,比如说string
int main()
{
string s1 = "GalaxyPokemon";
vector<int> v3(s1.begin(), s1.end());
for (auto e : v3)
{
cout << e << " ";
}
return 0;
} 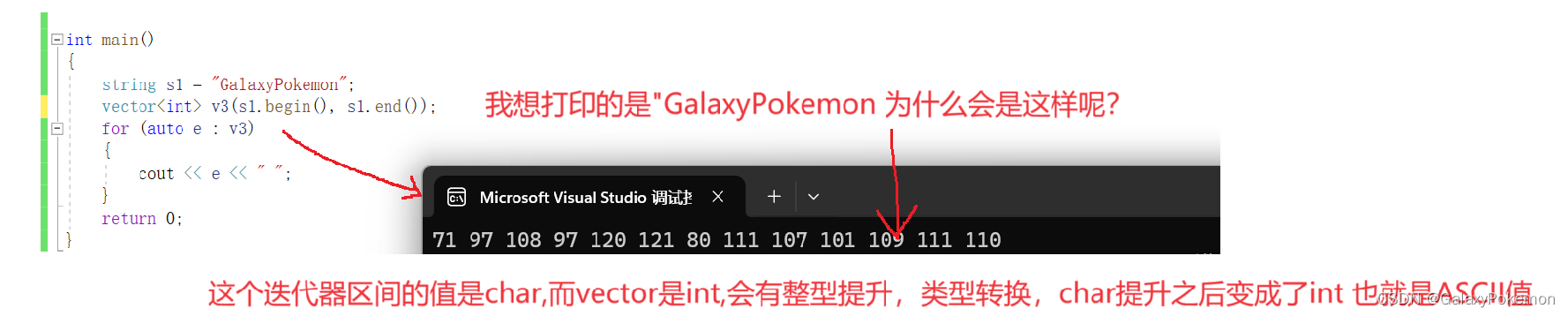
所以这样才是最准确的
int main()
{
string s1 = "GalaxyPokemon";
vector<char> v3(s1.begin(), s1.end());
for (auto e : v3)
{
cout << e << " ";
}
return 0;
} vector的元素访问
vector的元素访问
| 接口名称 | 使用说明 |
| operator[] | 访问元素 下标 + [ ] |
| at | 访问元素 下标 + ( ) |
| front | 访问第一个元素 |
| back | 访问最后一个元素 |
operator[ ]
reference operator[] (size_type n);
const_reference operator[] (size_type n) const;
//n:容器中元素的位置。注意,第一个元素的位置为0(不是1)。成员类型size_type是一个无符号整数类型。

int main()
{
vector<int> v(5, 1);
//使用“下标+[]”的方式遍历容器
for (size_t i = 0; i < v.size(); i++)
{
cout << v[i] << " ";
}
cout << endl;
return 0;
}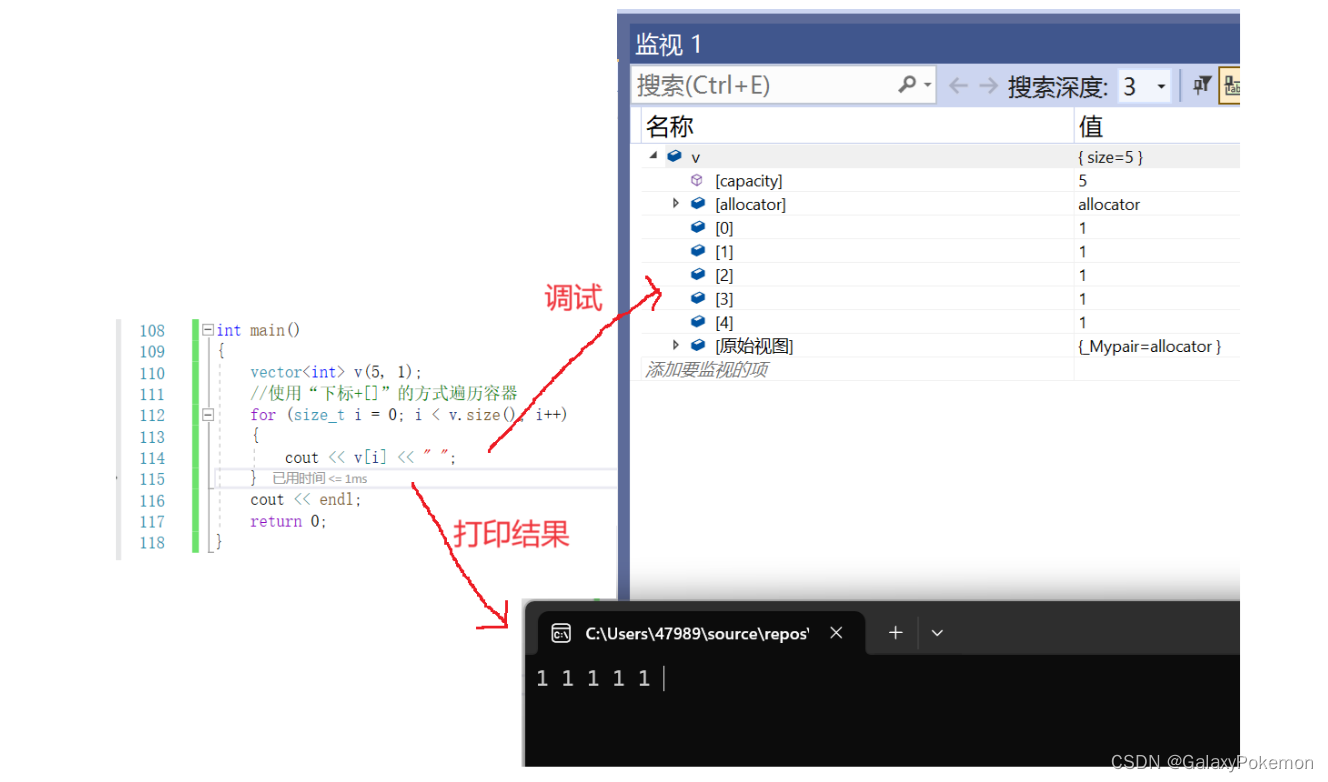 对于
对于oparator[]来说,若是产生了一个越界访问的话就直接报出【断言错误】了
at

reference operator[] (size_type n);
const_reference operator[] (size_type n) const;
//n:容器中元素的位置。注意,第一个元素的位置为0(不是1)。成员类型size_type是一个无符号整数类型。
int main()
{
vector<int> v(5, 1);
//使用“下标+()”的方式遍历容器
for (size_t i = 0; i < v.size(); i++)
{
cout << v.at(i) << " ";
}
cout << endl;
return 0;
}
front
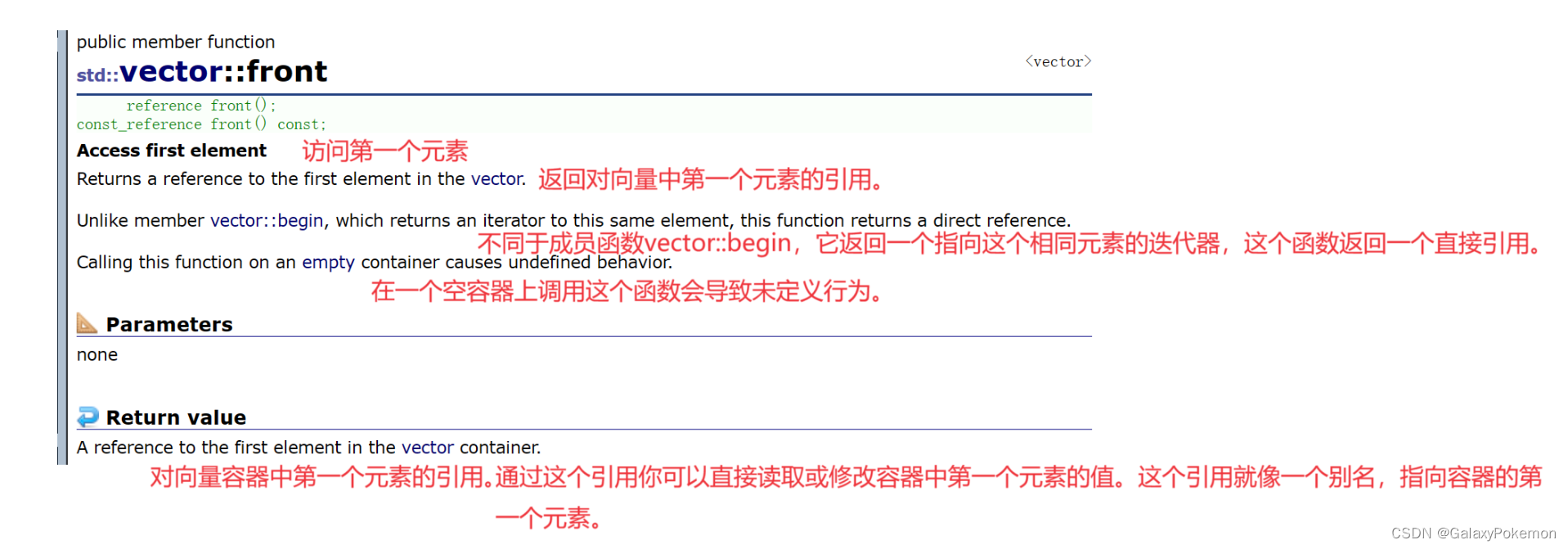
reference operator[] (size_type n);
const_reference operator[] (size_type n) const;
//n:容器中元素的位置。注意,第一个元素的位置为0(不是1)。成员类型size_type是一个无符号整数类型。
int main()
{
vector<int> v(5, 1);
cout << v.front() << endl;
return 0;
}
back
reference operator[] (size_type n);
const_reference operator[] (size_type n) const;
//n:容器中元素的位置。注意,第一个元素的位置为0(不是1)。成员类型size_type是一个无符号整数类型。
int main()
{
int arr[] = { 1,2,3,4 };
vector<int> v(arr, arr + 4);
cout << v.back() << endl;
return 0;
}
范围for
vector是支持迭代器的,所以我们还可以用范围for对vector容器进行遍历。(支持迭代器就支持范围for,因为在编译时编译器会自动将范围for替换为迭代器的形式)
int main()
{
vector<int> v(2, 10);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
return 0;
}
vector及迭代器的操作
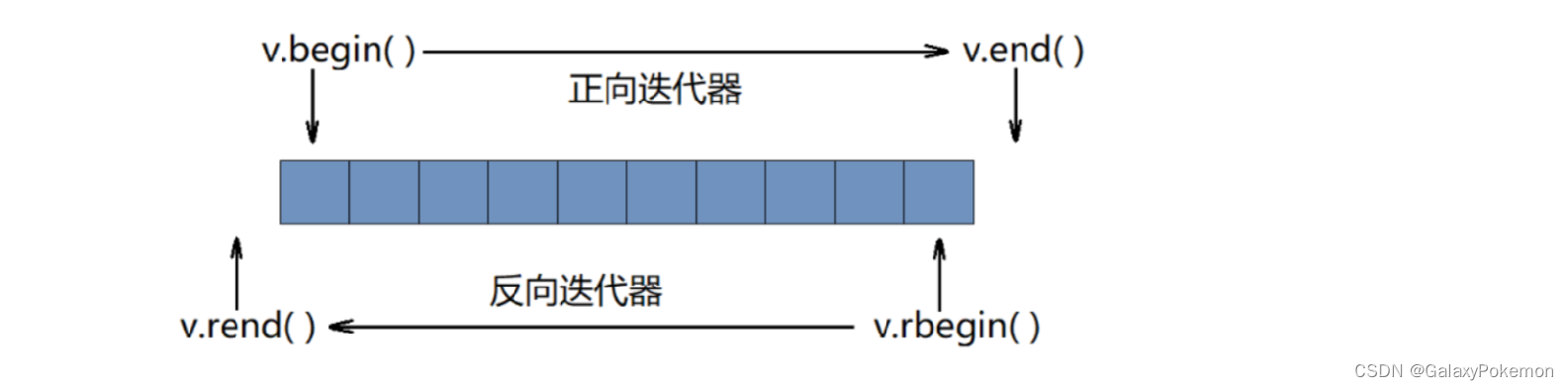
迭代器:
| 接口名称 | 使用说明 |
| begin | 返回指向第一个元素的迭代器 |
| end | 返回指向最后一个元素的下一个位置的迭代器 |
| rbegin | 返回指向最后一个元素的反向迭代器 |
| rend | 返回指向第一个元素的前一个位置的反向迭代器 |
 这些接口的用法和迭代器用法类似,如果想了解更多可以去迭代器文章里面查看
这些接口的用法和迭代器用法类似,如果想了解更多可以去迭代器文章里面查看
begin和end
通过begin函数可以得到容器中第一个元素的正向迭代器,通过end函数可以得到容器中最后一个元素的后一个位置的正向迭代器。
正向迭代器遍历容器:
int main()
{
vector<int> v(10, 2);
//正向迭代器遍历容器
vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
it++;
}
cout << endl;
return 0;
}
rbegin和rend
通过rbegin函数可以得到容器中最后一个元素的反向迭代器,通过rend函数可以得到容器中第一个元素的前一个位置的反向迭代器。
反向迭代器遍历容器:
int main()
{
vector<int> v(10, 2);
//反向迭代器遍历容器
vector<int>::reverse_iterator rit = v.rbegin();
while (rit != v.rend())
{
cout << *rit << " ";
rit++;
}
cout << endl;
return 0;
}
外传
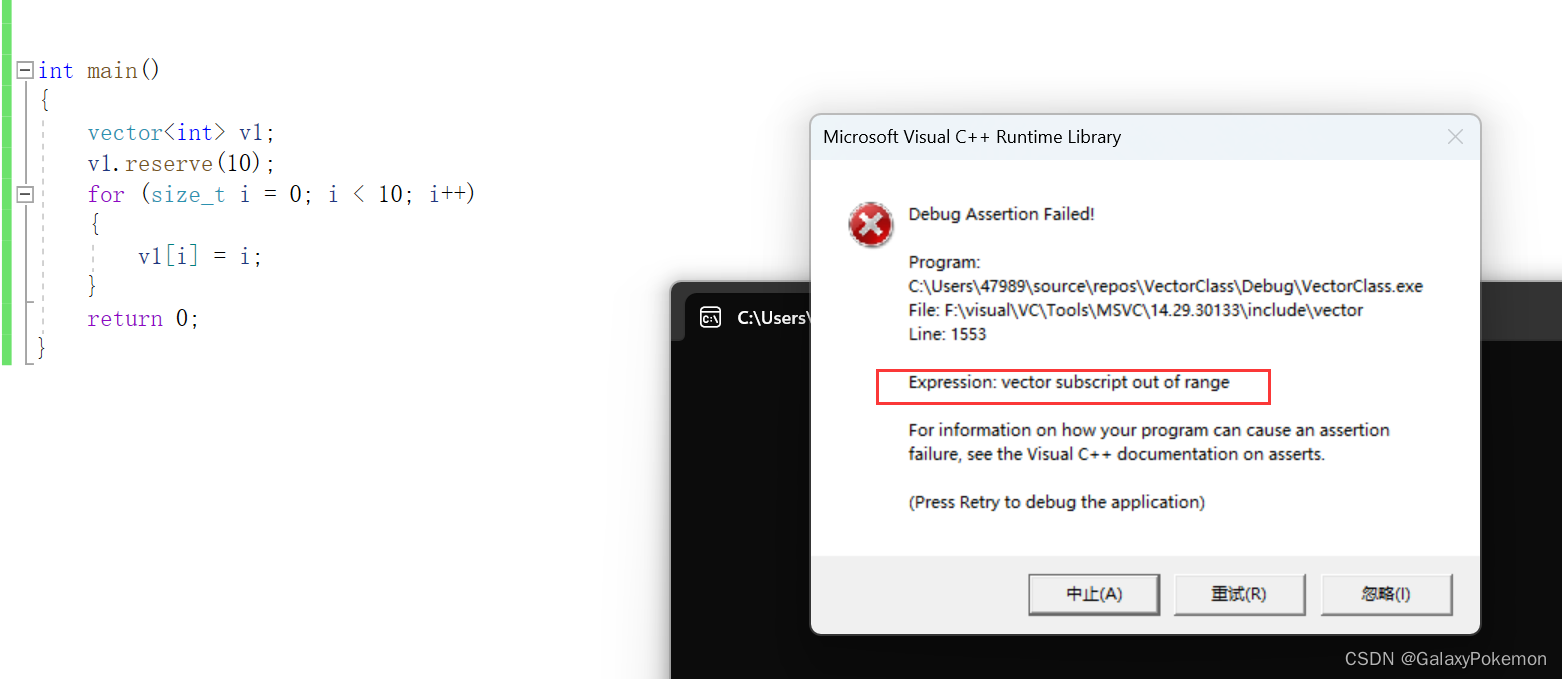
operator[]会检查越界,这里面的size为0,一检测就会越界
v1.reserve(10);这行代码只是预留了足够的空间来存储10个char类型的元素,但并没有实际创建这些元素。reserve函数只影响vector的容量,而不改变它的大小。循环中的
v1[i] = i;试图访问并赋值给vector的元素。由于v1的大小(size)实际上是0(没有包含任何元素),这里的访问是越界的,因为它尝试访问并写入未初始化的内存位置。为了修复这个问题,应该使用
push_back方法或者在调用reserve后使用resize来实际创建元素:push_back插入数据会依次把size给涨上去

二者都会对越界进行检查,at是抛异常,[]是断言, 断言更暴力一点
使用find查找3,并删除,如果有多个3应该怎么搞?

迭代器失效的问题,删除了第一个3之后,就会失效
在C++中,迭代器失效(Iterator invalidation)是指当容器发生某些修改操作(如添加、删除元素等)后,其迭代器不再指向有效的容器元素,或者不再有有效的行为。迭代器失效可能会导致未定义行为,包括访问无效内存,这在程序中可能会导致错误或崩溃。不同类型的容器对迭代器的失效规则各有不同:
1. vector和string
- 添加元素:当通过
push_back()或insert()向vector添加元素时,如果引发了重新分配(即容器当前的容量不足以容纳更多元素),则所有指向元素的迭代器、引用和指针都将失效。如果没有重新分配,那么只有指向插入点及之后元素的迭代器失效。 - 删除元素:使用
erase()删除vector或string中的元素会使从删除点开始到末尾的所有迭代器失效。
vector的常见容量接口
| 函数名称 | 功能 |
| size | 返回字符串有效字符长度 |
| resize | 扩容+初始化 |
| capacity | 返回分配的存储容量大小(即有效元素的最大容量) |
| empty | 检测字符串是否为空串,是返回true,否则返回false |
| reserve | 对容量进行改变 |
size
int main()
{
vector<int> v(10, 1);
cout << v.size() << endl;
return 0;
} 
resize
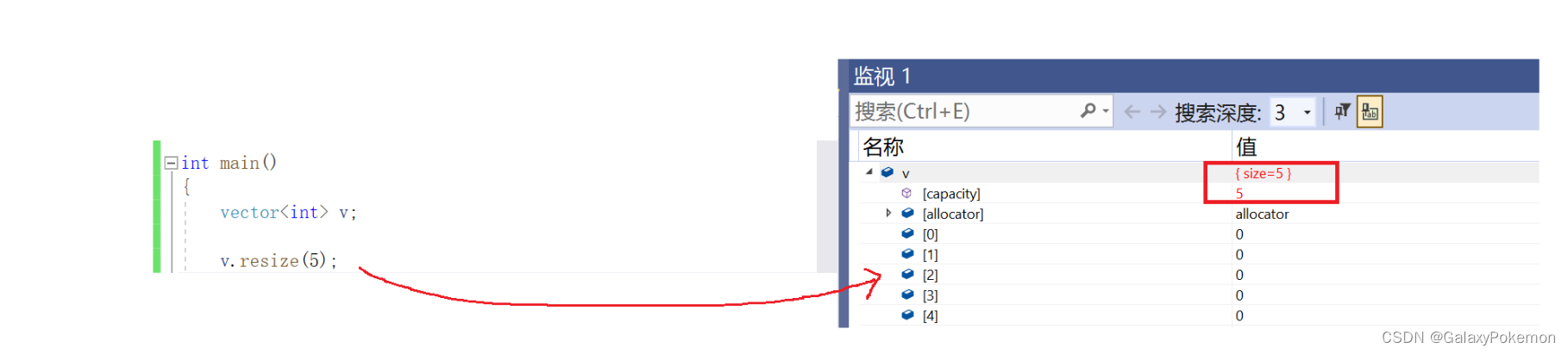
void resize (size_type n, value_type val = value_type());【resize】的功能则是 开空间 + 初始化,并且填上默认值
这一块我们要通过调试来进行观察

接着调用resize,看到调试窗口中的size发生了变化,而且新增了3个为0的数据值
capacity
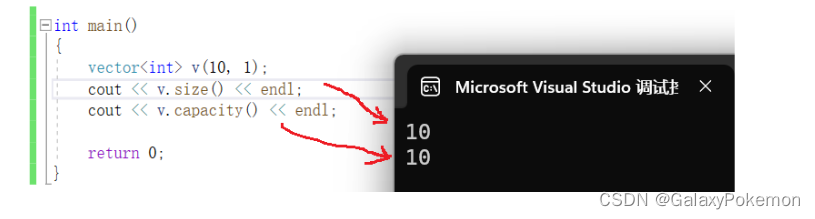
size_type capacity() const;对于capacity来说,就是容量大小,这里可以看到其与capacity是一同增长的,也为10
int main()
{
vector<int> v(10, 1);
cout << v.size() << endl;
cout << v.capacity() << endl;
return 0;
}
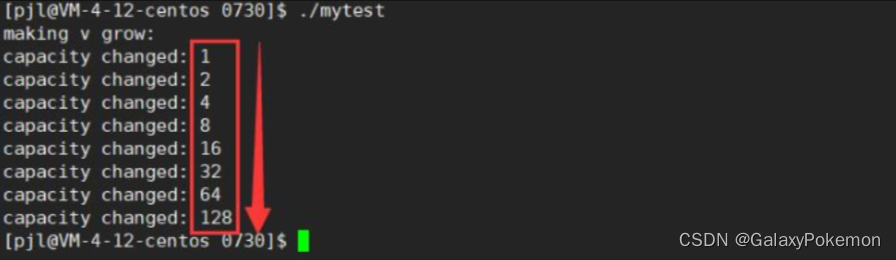
下面我们来看一下【vector】的默认扩容机制
// 测试vector的默认扩容机制
void TestVectorExpand()
{
size_t sz;
vector<int> v;
sz = v.capacity();
cout << "making v grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}通过运行结果我们可以发现,在VS下的扩容机制是呈现 1.5 进行增长的

但是呢,在 Linux 下却始终是呈现的一个2倍的扩容机制
empty
bool empty() const;int main()
{
vector<int> v;
cout << v.empty() << endl;
v.push_back(1);
v.push_back(2);
cout << v.empty() << endl;
return 0;
}
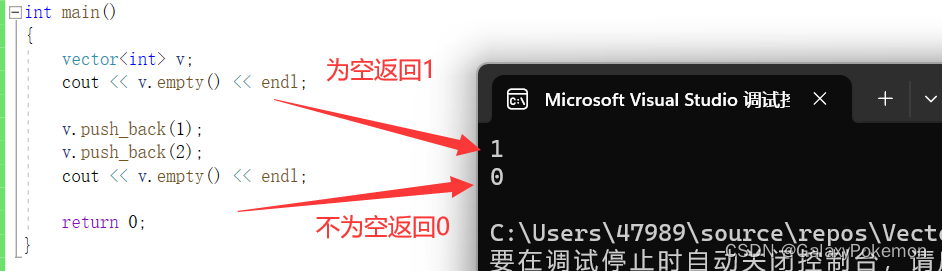
当一开始进在初始化后是为空,但是在插入数据后就不为空了
当size为 0 时,返回 1
当size为 非0 时,返回 0
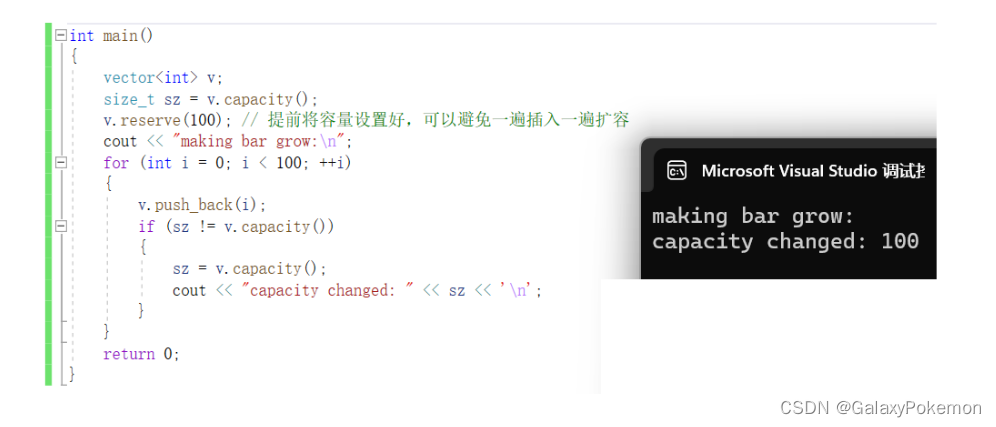
reserve
void reserve (size_type n);它的主要功能是 开空间,避免频繁扩容
int main()
{
vector<int> v;
size_t sz = v.capacity();
v.reserve(100); // 提前将容量设置好,可以避免一遍插入一遍扩容
cout << "making bar grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
return 0;
}
外传:【reserve】和【resize】在使用中的易错点
int main() { vector<int> v1; v1.reserve(10); for (size_t i = 0; i < 10; i++) { v1[i] = i; } return 0; }
有同学说:感觉这代码也没什么错呀?怎么会有错误呢?
大家要关注前面的reserve(10),我们在上面说到对于【reserve】而言只是做的扩容而已,即只变化capacity,而不会变化size
另一点,对于v1[i]我们上面在讲元素访问的时候有说到过,这是下标 + []的访问形式,在出现问题的时候会直接给出断言错误。因为这里我们在【reserve】的时候只是开出了指定的空间,但size还是为0,此时去访问的时候肯定就出错了正确改进的方法:
vector<int> v2; v2.resize(10); for (size_t i = 0; i < 10; i++) { v2[i] = i; }
- 或者呢,我们也可以写成下面这种形式。如果有同学还是要使用【reserve】的话就不要使用
下标 + []的形式了,而是使用【push_back】的方式去不断尾插数据,因为在不断尾插的过程中就会去做一个扩容,这一点马上就会讲到